Мы довольно часто пишем о технологии VMware VVols, которая позволяет организовывать виртуальные хранилища наиболее оптимально с точки зрения управления и производительности без файловой системы VMFS. Сегодня мы обсудим, как узнать, поддерживает ли ваш адаптер ввода-вывода технологию VMware VVols.
Начнем с того, почему адаптер и хранилище вообще должны ее поддерживать. Все просто - для доступа к томам VVols используется специальный служебный LUN, реализуемый в виде Protocol Endpoint (PE). Когда обычный FC-адаптер соединяется с хранилищем VMFS, он использует путь к LUN на базе адресов WWN, который состоит из номера HBA-адаптера, номера контроллера и, конечно же, LUN ID. Это все выглядит как vmhbaAdapter:CChannel:TTarget:LLUN (например, vmhba1:C0:T3:L1).
В случае с VVols и луном PE это уже работает несколько по-другому: появляются так называемые Secondary LUN IDs, которые адресуются как саблуны девайсом PE (secondary level IDs, SLLID). Этот Administrative LUN на устройстве PE не имеет емкости, но адресует тома VVols, которые находятся уже непосредственно на хранилище.
Сервер vCenter получает эти Secondary LUN IDs через механизм VASA Provider, реализованный через одноименный API. Далее уже хост ESXi (а точнее его I/O-адаптер, например, HBA-адаптер) работает в виртуальными машинами (а вернее с томами VVols) через Secondary LUN IDs (их, кстати, может быть не 255 как у LUN ID, а намного больше).
Надо отметить, что средства резервного копирования на уровне LUN не могут напрямую обратиться к этим Secondary LUN IDs, так как работа с ними идет только через хост VMware ESXi.
Так вот стандартная SCSI-команда REPORT_LUNS не подходит для обнаружения административных LUN, которые в отличие от LUN с данными, не имеют емкости. Поэтому VMware подала предложения в комитет T-10, отвечающий за SCSI-протокол, чтобы внести в его спецификацию некоторые изменения:
Самый простой способ узнать, поддерживает ли ваш FC/NFS-адаптер адресацию Secondary LUN IDs - это пойти в список совместимости VMware HCL:
В списке Features вы должны увидеть пункт Secondary LUNID (Enables VVols). Выберите его и посмотрите результат:
Тут уже видна подробная информация о драйвере и фича SLLID.
Далее можно заглянуть в ваш vmkernel.log и посмотреть нет ли там следующих строчек:
Sanity check failed for path vmhbaX:Y:Z. The path is to a VVol PE, but it goes out of adapter vmhbaX which is not PE capable. Path dropped.
Если есть - понятное дело, VVols не поддерживаются. Ну а в консоли сервера VMware ESXi параметры HBA-адаптера можно проверить следующей командой:
esxcli storage core adapter list
В колонке Capabilities будет видна строчка Second Level Lun ID, если поддержка VVols у вашего адаптера есть:
На стороне хранилища вам нужно убедиться, что VASA Provider включен и поддержка фич PE для VVols функционирует. Далее выполните следующую команду, чтобы убедиться, что хост ESXi видит девайс PE (обратите внимание, что он видится как диск):
esxcli storage core device list –pe-only
Если вы видите в строчке Is VVOL PE значение true, то значит все ок, и вы можете развертывать виртуальные машины на базе томов VVols.
Интересный пост вышел на одном из блогов компании VMware о производительности протокола VMware Horizon Blast Extreme, который используется совместно с технологией построения инфраструктуры производительных виртуальных десктопов NVIDIA GRID.
Не так давно мы писали о новых возможностях VMware Horizon 7, одной из которых стало полноценное включение протокола Blast Extreme на основе видеокодека H.264 в стек используемых протоколов наряду с PCoIP и RDP. Совместно с решением NVIDIA GRID производительность протокола Blast Extreme значительно возрастает, давайте посмотрим насколько.
В тесте команды NVIDIA GRID Performance Engineering Team использовался симулятор рабочей нагрузки ESRI ArcGIS Pro 1.1, который воспроизводил типичные действия пользователей а в качестве основных метрик снимались задержки (latency), фреймрейт (FPS), требуемая полоса пропускания (bandwidth) и прочие. При этом проводилось сравнение Blast Extreme (в программном варианте и при аппаратном ускорении GRID) с протоколом PCoIP, который широко используется в настоящий момент.
Благодаря ускорению обработки кодирования/декодирования на аппаратном уровне, уменьшаются задержки при выполнении операций (за счет ускорения обработки на стороне сервера):
Blast Extreme уменьшает задержку аж на 51 миллисекунду по сравнению с традиционным PCoIP.
По результатам теста для FPS производительность Blast Extreme превосходит PCoIP на целых 37%:
Для 19 виртуальных машин на одном сервере в тесте ESRI ArcGIS Pro 1.1 необходимая полоса пропускания для Blast Extreme была ниже на 19%, чем для PCoIP (и это без потерь качества картинки):
Благодаря кодеку H.264, который передает нагрузку на сторону выделенных аппаратных движков NVIDIA GPU, снижается нагрузка на центральный процессор хост-сервера VMware ESXi на 16%:
При этом удалось добиться увеличения числа пользователей на сервере ESXi на 18%, а это 3 человека на сервер.
Понятно, что тест ESRI ArcGIS Pro 1.1 не является универсальной нагрузкой, но в целом можно сказать, что Blast Extreme при аппаратном ускорении повышает производительность процентов на 15.
Среди больших анонсов компании VMware в рамках мероприятия Enabling the Digital Enterprise было также объявлено о сокром выпуске новой версии продукта VMware vCenter Log Insight 3.3 для управления файлами журнала (логами), сбора данных о виртуальной инфраструктуре, аналитики и поиска. Напомним, что о возможностях прошлой версии Log Insight 3.0 мы писали вот тут.
Итак, что же нового в VMware vRealize Log Insight 3.3:
1. Несколько адресов Virtual IP (VIP) с тэгированием или без него.
Интегрированный балансировщик vRealize Log Insight 3.3 теперь позволяет настроить несколько виртуальных адресов VIP с одним или несколькими тэгами или без них. Это позволяет тэгировать входящий трафик и упрощает настройку ролевой модели доступа для устройств, в которых нет агента Log Insight. Кроме того, это существенно увеличивает производительность.
Настройка производится на странице Cluster в секции Administration:
2. Поддержка Webhooks.
Теперь системные и пользовательские нотификации можно посылать через механизм webhooks, это позволяет настроить интеграцию с такими системами, как Socialcast, PagerDuty или кастомный канал RSS/Atom.
Алерты настраиваются в секции General:
Также нотификацию через webhooks можно настроить при создании нового алерта или редактировании существующего (также можно сразу протестировать алерт, послав тест):
3. Улучшенная интеграция с платформой VMware vSphere.
Для компонентов VMware vCenter и ESXi также могут быть добавлены тэги по аналогии с возможностью Multiple VIP with Tags, описанной в первом пункте.
В дополнение к этому, ненастроенные хосты ESXi могут быть добавлены в интеграцию с vSphere по умолчанию. Это можно настроить в опции "Advanced Configuration" во время настройки первоначальной интеграции или через пункт "View Details" для существующих интеграций (также обратите внимание на чекбокс "Automatically configure all ESXi hosts"):
4. Поддержка дополнительных свойств OVF.
Для виртуального модуля Log Insight могут быть настроены свойства DNS searchpath и DNS domain, также появились и другие улучшения:
5. Улучшения агентов Log Insight.
Здесь появилось множество улучшений.
Во-первых, добавлены новые парсеры для следующих форматов:
Во-вторых, появилась полная поддержка протокола IPv6.
В-третьих, появилась поддержка copytruncate для Linux-систем. Это когда содержимое открытого активного лога переносится в другой файл, а активный лог очищается - нужно это для тех приложений, которые не могут сами закрыть файл лога и переключиться на другой.
В-четвертых, появилась поддержка Windows 10.
6. Новые API.
Вот какие API были добавлены в Log Insight:
Authentication API - интерфейс для авторизации в Log Insight в целях дальнейшего выполнения операций.
Query API - возможность запросов к Log Insight и получения информации, в том числе в агрегированном виде.
Также появилась утилита Importer Utility, которая позволяет импортировать старые логи и саппорт-бандлы через Log Insight ingestion API. Она поставляется в виде исполняемого файла для Windows и Linux.
7. Новые возможности в статусе Tech Preview.
В Log Insight 3.3 компания VMware ввела несколько дополнительных возможностей, с которыми можно ознакомиться в экспериментальном режиме.
Agent Configuration Builder
Этот компонент позволяет посмотреть конфигурацию агента и пересобрать его с нужными параметрами. Делается это в разделе Agents:
Кроме того, сам виртуальный модуль VMware Log Insight 3.3 может быть полностью сконфигурирован с настройками IPv6. Также в состав платформы включены различные Configuration APIs, которые можно попробовать в режиме технологического превью.
На данный момент нет точной информации о доступности новой версии, но можно подписаться на рассылку о доступности VMware vRealize Log Insight 3.3 по этой ссылке.
Продолжаем рассказывать о технологиях компании StarWind, являющейся лидером в сфере решений для создания отказоустойчивых хранилищ под виртуальные машины на платформах VMware vSphere и Microsoft Hyper-V. Оказывается, прямо сейчас вы можете протестировать технологию VMware VVols совместно с решением StarWind Virtual SAN.
Для этого у компании StarWind есть специальный документ "StarWind Virtual SAN VVOLs Technical Preview Guide", рассказывающий о том, как попробовать виртуальные тома VVols для vSphere в режиме технологического превью в рамках тестовой инфраструктуры из одного хост-сервера.
Для тестирования нужно использовать виртуальный модуль StarWind VSA, который развертывается как виртуальная машина в формате OVF.
Для развертывания тестового стенда вам потребуется один сервер VMware ESXi 6.0 под управлением vCenter 6 в следующей минимальной конфигурации:
8 ГБ RAM
2GHz+ 64-bit x86 Dual Core CPU
2 vCPU, 4 ГБ RAM и 50 ГБ хранилища для машины StarWind
Компания VMware, оказывается, имеет интересный инструмент для расчета стоимости владения инфраструктурой хранения на базе локальных серверов VMware Virtual SAN TCO and Sizing Calculator. Понятно, что инструмент это больше маркетинговый, чем приложимый к реальному миру, но давайте все же взглянем на него. Напомним, кстати, также, что недавно была анонсирована новая версия VMware Virtual SAN 6.2.
Первое, что нам нужно ввести - это основные параметры инфраструктуры (можно выбрать между серверной виртуализацией и виртуализацией настольных ПК). Сначала нужно указать число виртуальных машин и число ВМ на сервер VMware ESXi. Далее можно использовать один для всех профиль виртуальной машины, а можно добавить несколько:
Если вы не знаете, что такое FTT (Failures to tolerates) - загляните вот в эту нашу заметку.
Далее мы вычисляем требуемую полезную емкость, необходимую для размещения виртуальных машин в кластерах Virtual SAN с учетом требуемого уровня отказоустойчивости:
Затем мы переходим к кастомизации так называемой "Ready Node" (об этом мы писали вот тут). Это типовой серверный узел, который будет исполнять как виртуальные машины, так и хранить их на своих локальных дисках.
Также в самом начале нужно задать "Performance profile", то есть типовую предполагаемую конфигурацию хранилища/производительности дисков для узла Virtual SAN. Внизу будет выведена примерная стоимость инфраструктуры хранения:
Кстати, у VMware есть инструмент Virtual SAN Ready Node Configurator, который поможет определиться с точной конфигурацией узла и создать спецификацию на него с учетом производителя серверов, которые вы обычно закупаете для своей инфраструктуры.
Ну а далее мы получаем overview из параметров, которыми будет обладать ваша виртуальная инфраструктура:
Ниже вы увидите распределение дискового пространства по VMDK-дискам, их репликам и прочим вспомогательным компонентам.
Внизу вы увидите конфигурацию хостов и кластера Virtual SAN, а также обобщенную спецификацию на узел. После этого переходим к параметрам расчета стоимости владения (TCO - total cost of ownership). Это такой метод сравнения затрат, когда вы сравниваете один способ реализации хранения машин без кластера хранилищ на базе локальных дисков с инфраструктурой Virtual SAN за определенный промежуток времени (обычно 3 или 5 лет).
Вводим параметры лицензирования и его тип, а также стоимость поддержки для Virtual SAN. Ниже вводим параметры текущей серверной конфигурации без VSAN:
Далее нам показывают "экономию" на трудозатратах (операционные издержки), а также на электропитании и охлаждении:
Ну а в конце приводится сводная таблица по капитальным и операционным затратам, полученная в сравнении использования Virtual SAN-конфигурации и развертывания традиционных дисковых массивов. Обратите внимание, что даже в дефолтном примере капитальные затраты с VSAN существенно выше:
Ниже идут различные графики про экономию денег в различных аспектах:
И в завершение - структура издержек на владение инфраструктурой хранения c VSAN и без него:
Инструмент интересный, но бесполезный. Пользуйтесь!
В этой заметке мы рассмотрим новые возможности решения для создания отказоустойчивых хранилищ на базе хост-серверов VMware Virtual SAN 6.2. Напомним, что о прошлой версии Virtual SAN 6.1, вышедшей осенью прошлого года, мы писали вот тут.
Итак, давайте посмотрим на новые возможности VSAN 6.2:
1. Дедупликация и сжатие данных.
Теперь обе этих технологии оптимизации хранилищ используются совместно, чтобы достичь наилучших результатов по стоимости хранения данных. Сначала данные виртуальных машин дедуплицируются на уровне дисковой группы, а потом сжимаются, что позволяет уменьшить исходный размер ВМ до 7 раз, в зависимости от типов нагрузки в гостевых ОС, по сравнению с первоначальным размещением.
Каждый vmdk хранит только оригинальные дисковые блоки:
2. Технология Erasure Coding (коррекция ошибок - "RAID из узлов").
В версии Virtual SAN 6.1 если вы используете параметр failures to tolerate =1 (FTT, зеркальная избыточность), то вам нужна двойная емкость в кластере. То есть, если будет 100 ГБ под виртуальные машины, то на хостах суммарная емкость должна составлять 200 ГБ.
По аналогии с RAID5/6 и другими типами RAID с чередованием, пространство хранения Virtual SAN 6.2 представляет собой "RAID из хостов ESXi". Таким образом, можно использовать схемы 3+1 или 4+2, которые позволят иметь лишь в 1,3 раза больше физического пространства (для первой схемы), чем полезной емкости. Об этом мы уже писали вот тут.
Вот интересная таблица соответствия параметров FTT, требований к инфраструктуре хранения и получаемых емкостей при различных типах RAID из хостов VMware ESXi:
3. Регулирование Quality of Service (QoS).
Теперь на уровне виртуальных дисков VMDK доступна регулировка полосы ввода-вывода на уровне IOPS:
Эти настройки могут быть применены через механизм политик хранилищ Storage Policy-Based Management (SPBM). Скорее всего, это будет востребовано в больших облачных инфраструктурах, особенно у сервис-провайдеров, которым необходимо обеспечивать различные уровни обслуживания своим клиентам. Также это позволяет создать механизм для того, чтобы рабочие нагрузки, размещенные на одном хранилище, не влияли друг на друга в моменты наибольшей нагрузки на подсистему хранения.
4. Техника Software Checksum.
Эта техника позволяет своевременно обнаруживать сбои, относящиеся к аппаратным и программным компонентам во время операций чтения/записи. Тут выделяются 2 типа сбоев: первый - "latent sector errors", который, как правило, свидетельствует о физической неисправности носителя, и второй - "silent data corruption", который происходит без предупреждения и может быть обнаружен только путем глубокой проверки поверхности накопителя.
5. Полноценная поддержка IPv6.
Теперь Virtual SAN поддерживает не только IPv4 и IPv6, но и смешанные окружения IPv4/IPv6 (для тех случаев, когда, например, на предприятии идет процесс миграции на новую версию протоколов).
6. Сервис мониторинга производительности.
Эти службы позволяют наблюдать за производительностью кластера Virtual SAN со стороны сервера vCenter. Теперь не обязательно идти в консоль vRealize Operations, чтобы решать базовые проблемы. Теперь в плане мониторинга доступны как высокоуровневые представления (Cluster latency, throughput, IOPS), так и более гранулярные (на базе дисков, попадания в кэш, статистика для дисковой группы и т.п.).
Также предусмотрена возможность предоставления данных о производительности кластера Virtual SAN сторонним сервисам через API. Для хранения событий используется собственная распределенная база данных, не зависящая от сервисов vCenter и хранящаяся в рамках кластера.
В этот раз мы рассмотрим сразу две функции Enable-VMHostSSH/Disable-VMHostSSH моего PowerCLI модуля для управления виртуальной инфраструктурой VMware Vi-Module.psm1. Очень часто администраторам виртуальной инфраструктуры требуется временно включить SSH на хосте/хостах ESXi, например, для запуска esxtop или для выяснения причин PSOD или для решения проблем с СХД...
Мы часто пишем о веб-консоли для управления отдельными хост-серверами VMware ESXi Embedded Host Client, которая для многих администраторов уже стала инструментом, используемым каждый день. На днях компания VMware выпустила обновленную версию ESXi Embedded Host Client v5, которая доступна для загрузки на сайте проекта VMware Labs.
На самом деле, нового в VMware ESXi Embedded Host Client 5 не так много, но говорят, что было исправлено очень много багов:
Хост-серверы
Улучшения в разделе мониторинга производительности (ресайз и поведение тултипов).
Виртуальные машины
Возможность простого экспорта виртуальной машины (базовые функции).
Поддержка клавиатур IT/ES в браузерной консоли.
Исправлены серьезные ошибки при операциях с дисковым контроллером (добавление/удаление, назначение дисков и т.п.).
Хранилища
Исправлена сортировка в datastore browser.
Общие улучшения
Улучшенное поведение таблиц (включая возможности выбора объектов, колонок и фильтрации).
Какое-то время назад мы писали о функции Data Locality, которая есть в решении для создания отказоустойчивых кластеров VMware Virtual SAN. Каждый раз, когда виртуальная машина читает данные с хранилища, они сохраняются в кэше (Read Cache) на SSD-накопителе, и эти данные могут быть востребованы очень быстро. Но в рамках растянутого кластера (vSphere Stretched Cluster) с высокой скоростью доступа к данным по сети передачи данных, возможно, фича Site / Data Locality вам не понадобится. Вот по какой причине.
Если ваши виртуальные машины часто переезжают с хоста на хост ESXi, при этом сами хосты географически разнесены в рамках VSAN Fault Domains, например, по одному зданию географически, то срабатывает функция Site Locality, которая требует, чтобы кэш на чтение располагался на том же узле/сайте, что и сами дисковые объекты машины. Это отнимает время на прогрев кэша хоста ESXi на новом месте для машины, а вот в скорости в итоге особой прибавки не дает, особенно, если у вас высокоскоростное соединение для всех серверов в рамках здания.
В этом случае Site Locality лучше отключить и не прогревать кэш каждый раз при миграциях в рамкха растянутого кластера с высокой пропускной способностью сети. Сначала запросим значение Site Locality:
Очередная функция Compare-VMHostSoftwareVibмоего PowerCLI-модуля для управления виртуальной инфраструктурой VMware Vi-Module.psm1 поможет вам сравнить установленные VIB-пакеты (vSphere Installation Bundle) между двумя и более хостами ESXi. Функция позволяет сравнивать как два отдельно взятых хоста, так и группу хостов, например, сравнить целый HA/DRS Cluster с эталонным хостом.
Компания VMware выпустила очень интересный документ "VMware vSphere 6
Fault Tolerance
Architecture and Performance", посвященный производительности технологии VMware Fault Tolerance (FT), которая позволяет обеспечивать непрерывную доступность виртуальных машин, даже в случае отказа хост-сервера VMware ESXi. Делается это за счет техники Fast Checkpointing, по своей сути похожей на комбинацию Storage vMotion и vMotion, которая копирует состояние дисков, памяти, процессорных команд и сетевого трафика на резервную машину, поддерживая ее в полностью синхронизированном с первой состоянии. На данный момент vSphere 6 FT поддерживает виртуальные машины с конфигурацией до 4 vCPU и до 64 ГБ оперативной памяти на хост ESXi.
Давайте посмотрим на интереснейшие результаты тестирования производительности, приведенные в документе.
1. Процедура компиляции ядра в гостевой ОС.
Эта процедура грузит CPU на 100%, поэтому посмотрим, каковы тут потери, связанные с аспектами производительности процессора и синхронной передачи команд. Все вполне хорошо, потери небольшие:
2. Сетевая активность.
Если говорить о производительности сетевой коммуникации, то на получение данных потерь практически нет, а вот на передачу все происходит процентов на 10 медленнее. Результат для 1 Гбит сети:
Кстати, очевидно, что сетевой трафик именно самой сети FT максимальный, когда машина принимает много данных (их нужно синхронизировать на второй узел), когда же данные передаются там трафик намного меньше (машина их просто отдает, а синхронизировать нужно только сам процесс передачи и параметры канала).
Результат для 10 Гбит сети. Вот тут и происходит ситуация, когда канал на прием забивается FT-трафиком, как итог - прием происходит только на полосе 2,4 Гбит:
Из-за необходимости поддержки параметров сетевой передачи и приема в синхронном режиме возникает Latency около 6 миллисекунд:
3. Тестирование подсистемы ввода-вывода.
Для тестирования работы с хранилищами (I/O) взяли стандартный инструмент IOMeter. Особых потерь не обнаружилось:
4. Тест Swingbench для Oracle 11g.
Для теста была взята OLTP-нагрузка на базу данных. По числу транзакций в секунду потери небольшие, но задержка по времени ответа возникает значительная:
5. Тест DVD Store на Microsoft SQL Server 2012.
Здесь была запущена симуляция 64 пользовательских сессий. По-сути, этот тест очень похож на методику для Oracle, ну и результаты здесь также соответствующие (но по времени отклика как-то все очень печально):
6. Бенчмарк на базе TPC-E.
Здесь были симулированы операции сервера брокерской компании, который производит обработку OLTP-транзакций в реальном времени. Тест очень стрессовый, и потери здесь весьма существенны:
7. Операции VMware vCenter Server.
Ну а здесь уже сам сервер vCenter защитили технологией Fault Tolerance и измерили производительность операций для двух типов нагрузки - легкой и тяжелой. При тяжелой нагрузке все происходит медленнее больше чем в 2 раза:
vSphere Web Client работает, в общем-то, неплохо, но хотелось бы лучше:
Результаты тестирования очень полезны - теперь администраторы смогут закладывать потери производительности на поддержание FT-кластера в архитектуру планируемой инфраструктуры для бизнес-критичных приложений.
Когда вы ставите один сервер VMware ESXi, то проще всего сделать это, смонтировав ISO-образ через iLO или подобную консоль, либо воткнув загрузочную флешку непосредственно в сервер. Но если у вас несколько хост-серверов ESXi, то делать так уже несолидно для опытного администратора. В целях ускорения процесса он использует процедуру загрузки установщика хоста по сети через механизм PXE, а самые крутые администраторы уже используют средство Auto Deploy, у которого сравнительно недавно появился GUI.
На эту тему компания VMware выпустила очень полезный документ "Installing ESXi Using PXE", в котором эта процедура расписывается по шагам (как для BIOS, так и для UEFI-хостов):
Интересна диаграмма зрелости процесса установки VMware ESXi в организации. Новички прожигают исошку на диск, а крутые перцы - используют Auto Deploy для stateless-хостов:
А вот, например, основная диаграмма последовательности процессов при установке ESXi через PXE:
По шагам процедура выглядит так:
1. Администратор загружает целевой хост ESXi.
2. Этот хост делает DHCP-запрос.
3. DHCP-сервер отвечает с IP-параметрами и расположением TFTP-сервера, который содержит загрузчик.
4. ESXi обращается к серверу TFTP и запрашивает файл загрузчика, который указал DHCP-сервер.
5. TFTP-сервер посылает загрузчик хосту ESXi, который исполняет его. Начальный загрузчик догружает дополнительные компоненты с TFTP-сервера.
6. Загрузчик ищет конфигурационный файл на TFTP-сервере, скачивает ядро и другие компоненты ESXi с HTTP-сервера, который размещен на TFTP-сервере, и запускает ядро на хосте ESXi.
7. Установщик ESXi запускается в интерактивном режиме, либо используя kickstart-скрипт, который указан в конфигурационном файле.
Для автоматизации задач по подготовке ISO-образа ESXi к загрузке через PXE вы можете использовать вот этот полезный скрипт.
Таги: VMware, ESXi, PXE, Boot, Auto Deploy, Whitepaper, vSphere
Идею для моей очередной функции Get-VMHostBirthday я позаимствовал из статьи известного блогера Магнуса Андерссона (Magnus Andersson), который задался интересным вопросом: «Как узнать дату и время установки хоста ESXi?». Вопрос, как оказалось, не такой уж простой, но решение, предложенное автором, мне показалось чересчур сложным по отношению к цене вопроса.
Вчера мы писали про режим воспроизведения, который можно использовать для утилиты esxtop, предназначенной мониторинга производительности хост-серверов VMware ESXi. А сегодня предлагаем вам скачать постер "vSphere 6 ESXTOP quick Overview for Troubleshooting", в котором приведена основная информация для начала работы с esxtop, а также базовые приемы по решению возникающих в виртуальной инфраструктуре проблем с производительностью. Также стоит заглянуть вот в эту и эту заметку на нашем сайте.
Постер можно повесить в админской или серверной, где часто приходится работать с консолью серверов ESXi:
Интересную новость мы обнаружили вот тут. Оказывается утилита esxtop может работать в режиме повтора для визуализации данных о производительности, собранных в определенный период времени (многие администраторы знают это, но далеко не все). Это позволит вам собрать данные о производительности хоста, например, ночью, а в течение рабочего дня проанализировать аномальное поведение виртуальной инфраструктуры VMware vSphere. Называется этот режим replay mode.
Для начала запустите следующую команду для сбора данных на хосте VMware ESXi:
Мы часто пишем о том, что снапшоты в VMware vSphere - это плохо (за исключением случаев, когда они используются для горячего резервного копирования виртуальных машин и временного сохранения конфигурации ВМ перед обновлением).
Однако их использование в крупных инфраструктурах неизбежно. Рано или поздно возникает необходимость удаления/консолидации снапшотов виртуальной машины (кнопка Delete All в Snapshot Manager), а процесс этот достаточно длительный и требовательный к производительности хранилищ, поэтому неплохо бы заранее знать, сколько он займет.
Напомним, что инициирование удаления снапшотов в vSphere Client через функцию Delete All приводит к их удалению из GUI сразу же, но на хранилище процесс идет долгое время. Но если в процесс удаления возникнет ошибка, то файлы снапшотов могут остаться на хранилище. Тогда нужно воспользоваться функцией консолидации снапшотов (пункт контекстного меню Consolidate):
О процессе консолидации снапшотов мы также писали вот тут. Удаление снапшотов (как по кнопке Delete All, так и через функцию Consolidate) называется консолидацией.
Сначала посмотрим, какие факторы влияют на время процесса консолидации снапшотов виртуальной машины:
Размер дельта-дисков - самый важный параметр, это очевидно. Чем больше данных в дельта-диске, тем дольше их нужно применять к основному (базовому) диску.
Количество снапшотов (число дельта-файлов) и их размеры. Чем больше снапшотов, тем больше метаданных для анализа перед консолидацией. Кроме того, при нескольких снапшотах консолидация происходит в несколько этапов.
Производительность подсистемы хранения, включая FC-фабрику, Storage Processor'ы хранилищ, LUN'ы (число дисков в группе, тип RAID и многое другое).
Тип данных в файлах снапшотов (нули или случайные данные).
Нагрузка на хост-сервер ESXi при снятии снапшота.
Нагрузка виртуальной машины на подсистему хранения в процессе консолидации. Например, почтовый сервер, работающий на полную мощность, может очень долго находится в процессе консолидации снапшотов.
Тут надо отметить, что процесс консолидации - это очень требовательный к подсистеме ввода-вывода процесс, поэтому не рекомендуется делать это в рабочие часы, когда производственные виртуальные машины нагружены.
Итак, как можно оценивать производительность процесса консолидации снапшотов:
Смотрим на производительность ввода-вывода хранилища, где находится ВМ со снапшотами.
Для реализации этого способа нужно, чтобы на хранилище осталась только одна тестовая виртуальная машина со снапшотами. С помощью vMotion/Storage vMotion остальные машины можно с него временно убрать.
1. Сначала смотрим размер файлов снапшотов через Datastore Browser или с помощью следующей команды:
ls -lh /vmfs/volumes/DATASTORE_NAME/VM_NAME | grep -E "delta|sparse"
2. Суммируем размер файлов снапшотов и записываем. Далее находим LUN, где размещена наша виртуальная машина, которую мы будем тестировать (подробнее об этом тут).
3. Запускаем команду мониторинга производительности:
# esxtop
4. Нажимаем клавишу <u> для переключения в представление производительности дисковых устройств. Для просмотра полного имени устройства нажмите Shift + L и введите 36.
5. Найдите устройство, на котором размещен датастор с виртуальной машиной и отслеживайте параметры в колонках MBREAD/s и MBWRTN/s в процессе консолидации снапшотов. Для того, чтобы нужное устройство было вверху экрана, можно отсортировать вывод по параметру MBREAD/s (нажмите клавишу R) or MBWRTN/s (нажмите T).
Таким образом, зная ваши параметры производительности чтения/записи, а также размер снапшотов и время консолидации тестового примера - вы сможете оценить время консолидации снапшотов для других виртуальных машин (правда, только примерно того же профиля нагрузки на дисковую подсистему).
Смотрим на производительность конкретного процесса консолидации снапшотов.
Это более тонкий процесс, который можно использовать для оценки времени снапшота путем мониторинга самого процесса vmx, реализующего операции со снапшотом в памяти сервера.
1. Запускаем команду мониторинга производительности:
# esxtop
2. Нажимаем Shift + V, чтобы увидеть только запущенные виртуальные машины.
3. Находим ВМ, на которой идет консолидация.
4. Нажимаем клавишу <e> для раскрытия списка.
5. Вводим Group World ID (это значение в колонке GID).
6. Запоминаем World ID (для ESXi 5.x процесс называется vmx-SnapshotVMX, для ранних версий SnapshotVMXCombiner).
7. Нажимаем <u> для отображения статистики дискового устройства.
8. Нажимаем <e>, чтобы раскрыть список и ввести устройство, на которое пишет процесс консолидации VMX. Что-то вроде naa.xxx.
9. Смотрим за процессом по World ID из пункта 6. Можно сортировать вывод по параметрам MBREAD/s (клавиша R) или MBWRTN/s (клавиша T).
10. Отслеживаем среднее значение в колонке MBWRTN/s.
Это более точный метод оценки и его можно использовать даже при незначительной нагрузке на хранилище от других виртуальных машин.
Напомним, что Veeam Availability Suite - это самое продвинутое в отрасли решение для всесторонней защиты данных средствами резервного копирования и репликации, а также набор продуктов для управления и мониторинга виртуальной среды. По-сути, это все что нужно, кроме самой платформы VMware vSphere или Microsoft Hyper-V, чтобы организовать виртуальный датацентр с непрерывной доступностью сервисов в виртуальных машинах.
Приведем ниже основные новые возможности Veeam Availability Suite v9, касающиеся его основного компонента - Veeam Backup and Replication 9:
1. Интеграция с технологией EMC Storage Snapshots в Veeam Availability Suite v9.
Многие пользователи Veeam Backup and Replication задавали вопрос, когда же будет сделана интеграция с дисковыми массивами EMC. Теперь она добавлена для СХД линеек EMC VNX и EMC VNXe.
Интеграция с хранилищами EMC означает поддержку обеих техник - Veeam Explorer for Storage Snapshots recovery и Backup from Storage snapshots, то есть можно смотреть содержимое снапшотов уровня хранилища и восстанавливать оттуда виртуальные машины (и другие сущности - файлы или объекты приложений), а также делать бэкап из таких снапшотов.
Иллюстрация восстановления из снапшота на хранилище EMC:
Иллюстрация процесса резервного копирования (Veeam Backup Proxy читает данные напрямую со снапшота всего тома, сделанного на хранилище EMC):
Более подробно об этих возможностях можно почитать в блоге Veeam.
2. Veeam Cloud Connect - теперь с возможностью репликации.
Как вы помните, в прошлом году компания Veeam выпустила средство Veeam Cloud Connect, которое позволяет осуществлять резервное копирование в облако практически любого сервис-провайдера. Теперь к этой возможности прибавится еще и возможность репликации ВМ в облако, что невероятно удобно для быстрого восстановления работоспособности сервисов в случае большой или маленькой беды:
Кстати, Veeam Cloud Connect инкапуслирует весь передаваемый трафик в один-единственный порт, что позволяет не открывать диапазоны портов при соединении с инфраструктурой сервис-провайдера. Очень удобно.
При восстановлении в случае аварии или катастрофы основного сайта, возможно не только полное восстановление инфраструктуры, но и частичное - когда часть продуктивной нагрузки запущено на основной площадке, а другая часть (например, отказавшая стойка) - на площадке провайдера. При этом Veeam Backup обеспечивает сетевое взаимодействие между виртуальными машинами обеих площадок за счет встроенных компонентов (network extension appliances), которые обеспечивают сохранение единого пространства адресации.
Ну а сервис-провайдеры с появлением репликации от Veeam получают в свои руки полный спектр средств для организации DR-площадки в аренду для своих клиентов:
Более подробно об этой возможности можно прочитать в блоге Veeam по этой ссылке.
3. Прямой доступ к хранилищам NAS/NFS при резервном копировании.
Veeam Availability Suite v9 поддерживает прямой доступ к хранилищам NAS/NFS при резервном копировании. Раньше пользователи NFS-массивов чувствовали себя несколько "обделенными" в возможностях, так как Veeam не поддерживал режим прямой интеграции с таким типом дисковым массивов, как это было для блочных хранилищ.
Теперь же появилась штука, называемая Direct NFS, позволяющая сделать резервную копию ВМ по протоколам NFS v3 и новому NFS 4.1 (его поддержка появилась только в vSphere 6.0), не задействуя хост-сервер для копирования данных:
Специальный клиент NFS (который появился еще в 8-й версии) при включении Direct NFS получает доступ к файлам виртуальных машин на томах, для которых можно делать резервное копирование и репликацию без участия VMware ESXi, что заметно повышает скорость операций.
Кроме этого, была улучшена поддержка дисковых массивов NetApp. В версии 9 к интеграции с NetApp добавилась поддержка резервного копирования из хранилищ SnapMirror и SnapVault. Теперь можно будет создавать аппаратные снимки (с учетом состояния приложений) с минимальным воздействием на виртуальную среду, реплицировать точки восстановления на резервный дисковый массив NetApp с применением техник SnapMirror или SnapVault, а уже оттуда выполнять бэкап виртуальных машин.
При этом процесс резервного копирования не отбирает производительность у основной СХД, ведь операции ввода-вывода происходят на резервном хранилище:
Ну и еще одна полезная штука в плане поддержки аппаратных снимков хранилищ от Veeam. Теперь появится фича Sandbox On-Demand, которая позволяет создать виртуальную лабораторию, запустив виртуальные машины напрямую из снапшотов томов уровня хранилищ. Такая лаборатория может быть использована как для проверки резервных копий на восстановляемость (сразу запускаем ВМ и смотрим, все ли в ней работает, после этого выключаем лабораторию, оставляя резервные копии неизменными), так и для быстрого клонирования наборов сервисов (создали несколько ВМ, после чего создали снапшот и запустили машины из него). То есть, можно сделать как бы снимок состояния многомашинного сервиса (например, БД-сервер приложений-клиент) и запустить его в изолированном окружении для тестов, ну или много чего еще можно придумать.
Вот здесь вы можете узнать больше подробностей об этой возможности в блоге Veeam.
Очередная функция Get-VMHostFirmwareVersion моего PowerCLI модуля для управления виртуальной инфраструктурой VMware Vi-Module.psm1 поможет вам узнать версию и дату выпуска Firmware ваших серверов ESXi. Для большей гибкости и удобства в использовании, функция написана в виде PowerShell-фильтра.
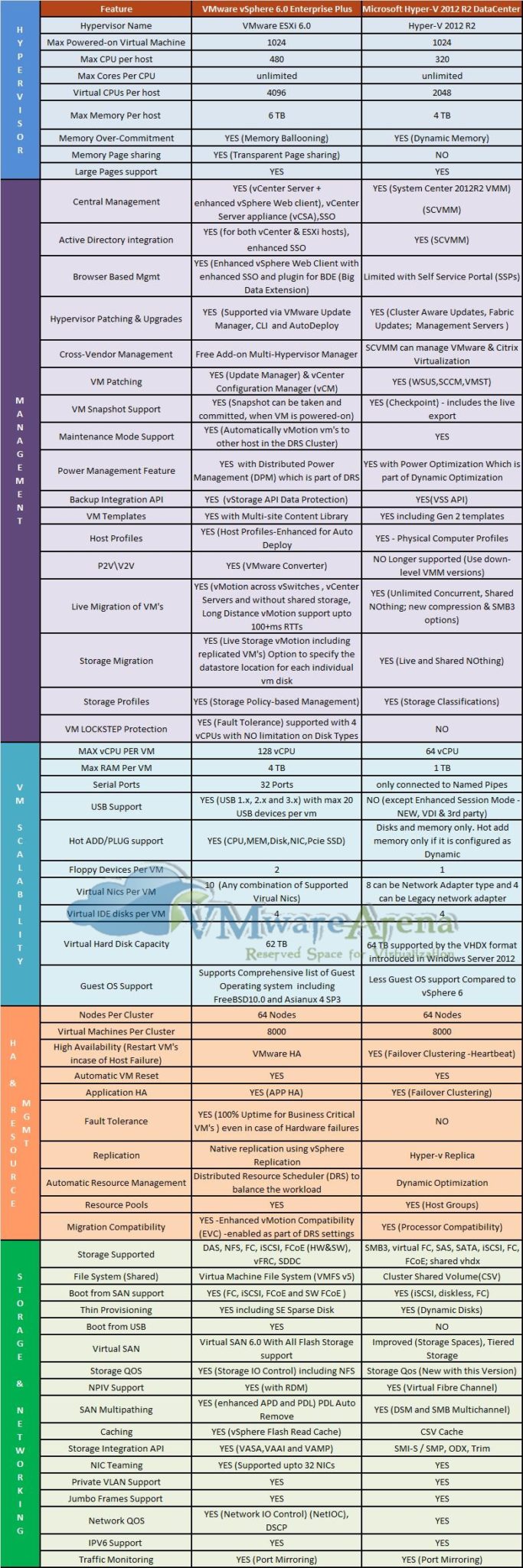
Не так давно на сайте VMwareArena появилось очередное сравнение VMware vSphere (в издании Enterprise Plus) и Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition, которое включает в себя самую актуальную информацию о возможностях обеих платформ.
Мы адаптировали это сравнение в виде таблицы и представляем вашему вниманию ниже:
Группа возможностей
Возможность
VMware vSphere 6
Enterprise Plus
Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
Возможности гипервизора
Версия гипервизора
VMware ESXi 6.0
Hyper-V 2012 R2
Максимальное число запущенных виртуальных машин
1024
1024
Максимальное число процессоров (CPU) на хост-сервер
480
320
Число ядер на процессор хоста
Не ограничено
Не ограничено
Максимальное число виртуальных процессоров (vCPU) на хост-сервер
4096
2048
Максимальный объем памяти (RAM) на хост-сервер
6 ТБ
4 ТБ
Техники Memory overcommitment (динамическое перераспределение памяти между машинами)
Memory ballooning
Dynamic Memory
Техники дедупликации страниц памяти
Transparent page sharing
Нет
Поддержка больших страниц памяти (Large Memory Pages)
Да
Да
Управление платформой
Централизованное управление
vCenter Server + vSphere Client + vSphere Web Client, а также виртуальный модуль vCenter Server Appliance (vCSA)
System Center Virtual Machine Manager (SC VMM)
Интеграция с Active Directory
Да, как для vCenter, так и для ESXi-хостов через расширенный механизм SSO
Да (через SC VMM)
Поддержка снапшотов (VM Snapshot)
Да, снапшоты могут быть сделаны и удалены для работающих виртуальных машин
Да, технология Checkpoint, включая функции live export
Управление через браузер (тонкий клиент)
Да, полнофункциональный vSphere Web Client
Ограниченное, через Self Service Portal
Обновления хост-серверов / гипервизора
Да, через VMware Update Manager (VUM), Auto Deploy и CLI
Да - Cluster Aware Updates, Fabric Updates, Management Servers
Управление сторонними гипервизорами
Да, бесплатный аддон Multi-Hypervisor Manager
Да, управление VMware vCenter и Citrix XenCenter поддерживается в SC VMM
Обновление (патчинг) виртуальных машин
Да, через VMware Update Manager (VUM) и vCenter Configuration Manager (vCM)
Да (WSUS, SCCM, VMST)
Режим обслуживания (Maintenance Mode)
Да, горячая миграция ВМ в кластере DRS на другие хосты
Да
Динамическое управление питанием
Да, функции Distributed Power Management в составе DRS
Да, функции Power Optimization в составе Dynamic Optimization
API для решений резервного копирования
Да, vStorage API for Data Protection
Да, VSS API
Шаблоны виртуальных машин (VM Templates)
Да + Multi-site content library
Да, включая шаблоны Gen2
Профили настройки хостов (Host Profiles)
Да, расширенные функции host profiles и интеграция с Auto Deploy
Да, функции Physical Computer Profiles
Решение по миграции физических серверов в виртуальные машины
Да, VMware vCenter Converter
Нет, больше не поддерживается
Горячая миграция виртуальных машин
Да, vMotion между хостами, между датацентрами с разными vCenter, Long Distance vMotion (100 ms RTT), возможна без общего хранилища
Да, возможна без общего хранилища (Shared Nothing), поддержка компрессии и SMB3, неограниченное число одновременных миграций
Горячая миграция хранилищ ВМ
Да, Storage vMotion, возможность указать размещение отдельных виртуальных дисков машины
Да
Профили хранилищ
Да, Storage policy-based management
Да, Storage Classifications
Кластер непрерывной доступности ВМ
Да, Fault Tolerance с поддержкой до 4 процессоров ВМ, поддержка различных типов дисков, технология vLockstep
Нет
Конфигурации виртуальных машин
Виртуальных процессоров на ВМ
128 vCPU
64 vCPU
Память на одну ВМ
4 ТБ
1 ТБ
Последовательных портов (serial ports)
32
Только присоединение к named pipes
Поддержка USB
До 20 на одну машину (версии 1,2 и 3)
Нет (за исключением Enhanced Session Mode)
Горячее добавление устройств
(CPU/Memory/Disk/NIC/PCIe SSD)
Только диск и память (память только, если настроена функция Dynamic memory)
Диски, растущие по мере наполнения данными (thin provisioning)
Да (thin disk и se sparse)
Да, Dynamic disks
Поддержка Boot from USB
Да
Нет
Хранилища на базе локальных дисков серверов
VMware Virtual SAN 6.0 с поддержкой конфигураций All Flash
Storage Spaces, Tiered Storage
Уровни обслуживания для подсистемы ввода-вывода
Да, Storage IO Control (работает и для NFS)
Да, Storage QoS
Поддержка NPIV
Да (для RDM-устройств)
Да (Virtual Fibre Channel)
Поддержка доступа по нескольким путям (multipathing)
Да, включая расширенную поддержку статусов APD и PDL
Да (DSM и SMB Multichannel)
Техники кэширования
Да, vSphere Flash Read Cache
Да, CSV Cache
API для интеграции с хранилищами
Да, широкий спектр VASA+VAAI+VAMP
Да, SMI-S / SMP, ODX, Trim
Поддержка NIC Teaming
Да, до 32 адаптеров
Да
Поддержка Private VLAN
Да
Да
Поддержка Jumbo Frames
Да
Да
Поддержка Network QoS
Да, NetIOC (Network IO Control), DSCP
Да
Поддержка IPv6
Да
Да
Мониторинг трафика
Да, Port mirroring
Да, Port mirroring
Подводя итог, скажем, что нужно смотреть не только на состав функций той или иной платформы виртуализации, но и необходимо изучить, как именно эти функции реализованы, так как не всегда реализация какой-то возможности позволит вам использовать ее в производственной среде ввиду различных ограничений. Кроме того, обязательно нужно смотреть, какие функции предоставляются другими продуктами от данного вендора, и способны ли они дополнить отсутствующие возможности (а также сколько это стоит). В общем, как всегда - дьявол в деталях.
Таги: VMware, vSphere, Hyper-V, Microsoft, Сравнение, ESXi, Windows, Server
Компания VMware выпустила первое после нового года обновление своей серверной платформы виртуализации - VMware vSphere 6.0 Update 1b, включая обновления vCenter и ESXi.
Новых возможностей, конечно же, немного, но все же компоненты vSphere рекомендуется обновить ввиду наличия критичных обновлений подсистемы безопасности.
Что нового в VMware vCenter Server 6.0 Update 1b:
Поддержка метода обновления URL-based patching с использованием zip-пакета. Подробнее в KB 2142009.
Пользовательские настройки для Client Integration Plugin или диалогового окна VMware-csd guard в vSphere Web Client могут быть переопределены. Подробнее в KB 2142218.
vSphere 6.0 Update 1b включает поддержку TLS версий 1.1 и 1.2 для большинства компонентов vSphere без нарушения совместимости с предыдущими версиями. Компоненты которые по-прежнему поддерживают только TLS версии 1.0:
vSphere Client
Virtual SAN Observer на сервере vCenter Server Appliance (vCSA)
Syslog на сервере vCSA
Auto Deploy на vCSA
Auto Deploy на iPXE
О поддержке TLS-протоколов можно почитать подробнее в KB 2136185 .
Утилита certificate manager теперь автоматически вызывает скрипт updateExtensionCertInVC.py для обновления хранилищ сертификатов, которые построены не на базе VMware Endpoint Certificate Store (VECS).
Множество исправлений ошибок.
Что нового в VMware ESXi 6.0 Update 1b:
Поддержка TLS версий 1.1 и 1.2 для большинства компонентов без нарушения совместимости с предыдущими версиями.
Поддержка Advanced Encryption Standard (AES) с длиной ключа 128/256 бит для аутентификации через NFS 4.1 Client.
Исправления ошибок.
Скачать VMware vCenter Server 6.0 Update 1b и VMware ESXi 6.0 Update 1b можно по этой ссылке.
Иногда системному администратору VMware vSphere требуется узнать, сколько тот или иной хост ESXi работает с момента последней загрузки (например, требуется проверить, не было ли внеплановых ребутов).
Есть аж целых 5 способов сделать это, каждый из них можно применять в зависимости от ситуации.
1. Самый простой - команда uptime.
Просто заходим на хост ESXi из консоли или по SSH и выполняем команду uptime:
login as: root
Using keyboard-interactive authentication.
Password: XXXXXX
The time and date of this login have been sent to the system logs.
VMware offers supported, powerful system administration tools. Please
see www.vmware.com/go/sysadmintools for details.
The ESXi Shell can be disabled by an administrative user. See the
vSphere Security documentation for more information.
~ # uptime
04:26:24 up 00:20:42, load average: 0.01, 0.01, 0.01
2. С помощью команды esxtop.
С помощью утилиты esxtop можно не только отслеживать производительность хоста в различных аспектах, но и узнать его аптайм. Обратите внимание на самую первую строчку вывода:
# esxtop
4. Время запуска хоста из лога vmksummary.log.
Вы можете посмотреть не только время текущего аптайма хоста ESXi, но времена его прошлых запусков в логе vmksummary.log. Для этого выполните следующую команду:
cat /var/log/vmksummary.log |grep booted
2015-06-26T06:25:27Z bootstop: Host has booted
2015-06-26T06:47:23Z bootstop: Host has booted
2015-06-26T06:58:19Z bootstop: Host has booted
2015-06-26T07:05:26Z bootstop: Host has booted
2015-06-26T07:09:50Z bootstop: Host has booted
2015-07-08T05:32:17Z bootstop: Host has booted
4. Аптайм в vSphere Client и Web Client.
Если вы хотите вывести аптайм сразу всех виртуальных машин на хосте в VMware vSphere Client, для этого есть специальная колонка в представлении Hosts:
5. Аптайм хостов через PowerCLI.
Конечно же, время работы хоста ESXi можно посмотреть и через интерфейс PowerCLI. Для этого нужно воспользоваться командлетом Get-VMHost:
Недавно мы писали о новой функции решения vGate 3.0 for Hyper-V, предназначенного для защиты виртуальной инфраструктуры Microsoft от несанкционированного доступа и безопасной ее конфигурации средствами политик безопасности. В преддверии выхода vGate 3.0 для обеих платформ виртуализации, vSphere и Hyper-V, мы расскажем о некоторых новых функциях продукта, которые будут доступны в обоих изданиях в первом квартале 2016 года.
Какое-то время назад мы писали о технологии доставки приложений пользователям инфраструктуры настольных ПК предприятия - VMware App Volumes (ранее это называлось Cloud Volumes). Суть ее заключается в том, что виртуализованные и готовые к использованию приложения VMware ThinApp доставляются пользователям в виде подключаемых виртуальных дисков к машинам.
Недавно компания VMware выпустила документ "VMware App Volumes Reference Architecture", в котором объясняется работа технологии App Volumes, рассматривается референсная архитектура этого решения, а также проводится тестирование производительности доставляемых таким образом приложений по сравнению с их нативной установкой внутри виртуальных ПК:
Собственно, типовая архитектура решения App Volumes выглядит следующим образом:
Здесь показаны основные компоненты такой инфраструктуры:
AppStacks - это тома, которые содержат сами установленные приложения и работают в режиме Read Only. Их можно назначить пользователям Active Directory, группам или OU. Один такой диск может быть назначен сразу нескольким виртуальным ПК (по умолчанию доступен всем машинам датацентра).
Writable Volumes - это персонализированные тома, которые принадлежат пользователям. Они хранят настройки приложений, лицензионную информацию, файлы конфигураций приложений и сами приложения, которые пользователь установил самостоятельно. Один такой диск может быть назначен только одному десктопу, но его можно перемещать между десктопами.
App Volumes Manager Server - это Windows-сервер, содержащий административную консоль для настройки продукта и управления им.
В качестве референсной архитектуры используется инфраструктура из 2000 виртуальных ПК, запущенных на 18 хостах ESXi инфраструктуры VMware Horizon View:
Для генерации нагрузки использовались различные сценарии пользовательского поведения, создаваемые с помощью средства Login VSI, ставшего уже стандартом де-факто для тестирования VDI-инфраструктур, развернутого на трех хост-серверах.
Здесь описаны 3 варианта тестирования:
Приложения, нативно установленные в виртуальных ПК.
Приложения App Volumes, использующие один AppStack, содержащий основные приложения пользователей.
Приложения App Volumes, распределенные по трем различным AppStack.
Для обоих случаев тестирования App Volumes использовался один Writable Volume. Тут были получены следующие результаты (больше очков - это лучше).
Посмотрим на время логина пользователей при увеличении числа одновременных сессий в референсной архитектуре:
Взглянем на время отклика приложений:
Оценим время запуска приложений:
В целом-то, нельзя сказать, что потери производительности незначительные - они, безусловно, чувствуются. Но радует, что они фиксированы и хорошо масштабируются при увеличении числа одновременных сессий в VDI-инфраструктуре.
Документ очень полезен для оценки потерь производительности с точки зрения User Experience при использовании App Volumes по сравнению с традиционной доставкой приложений. Скачать 50-страничный документ можно скачать по этой ссылке - почитайте, там действительно интересно все изложено.
Если вы посмотрите в документ VSAN Troubleshooting Reference Manual (кстати, очень нужный и полезный), описывающий решение проблем в отказоустойчивом кластере VMware Virtual SAN, то обнаружите там такую расширенную настройку, как VSAN.ClomMaxComponentSizeGB.
Когда кластер VSAN хранит объекты с данными виртуальных дисков машин, он разбивает их на кусочки, растущие по мере наполнения (тонкие диски) до размера, указанного в данном параметре. По умолчанию он равен 255 ГБ, и это значит, что если у вас физические диски дают полезную емкость меньше данного объема (а точнее самый маленький из дисков в группе), то при достижении тонким диском объекта предела физической емкости вы получите вот такое сообщение:
There is no more space for virtual disk XX. You might be able to continue this session by freeing disk space on the relevant volume and clicking retry.
Если, например, у вас физический диск на 200 ГБ, а параметры FTT и SW равны единице, то максимально объект виртуального диска машины вырастет до этого размера и выдаст ошибку. В этом случае имеет смысл выставить настройку VSAN.ClomMaxComponentSizeGB на уровне не более 80% емкости физического диска (то есть, в рассмотренном случае 160 ГБ). Настройку эту нужно будет применить на каждом из хостов кластера Virtual SAN.
Как это сделать (более подробно об этом - в KB 2080503):
В vSphere Web Client идем на вкладку Manage и кликаем на Settings.
Под категорией System нажимаем Advanced System Settings.
Выбираем элемент VSAN.ClomMaxComponentSizeGB и нажимаем иконку Edit.
Устанавливаем нужное значение.
Надо отметить, что изменение этой настройки работает только для кластера VSAN без развернутых на нем виртуальных машин. Если же у вас уже продакшен-инфраструктура столкнулась с такими трудностями, то вы можете воспользоваться следующими двумя способами для обхода описанной проблемы:
1. Задать Object Space Reservation в политике хранения (VM Storage Policy) таким образом, чтобы дисковое пространство под объекты резервировалось сразу (на уровне 100%). И тогда VMDK-диски будут аллоцироваться целиком и распределяться по физическим носителям по мере необходимости.
2. Задать параметр Stripe Width в политиках VM Storage Policy таким образом, чтобы объекты VMDK распределялись сразу по нескольким физическим накопителям.
Фишка еще в том, что параметрVSAN.ClomMaxComponentSizeGB не может быть выставлен в значение, меньшее чем 180 ГБ, а значит если у вас носители меньшего размера (например, All-Flash конфигурация с дисками меньше чем 200 ГБ) - придется воспользоваться одним из этих двух способов, чтобы избежать описанной ошибки. Для флеш-дисков 200 ГБ установка значения в 180 ГБ будет ок, несмотря на то, что это уже 90% физической емкости.
Мы уже не раз писали про веб-консоль управления ESXi Embedded Host Client, которая доступна на сайте проекта VMware Labs как VIB-пакет для вашего сервера ESXi. Вот тут мы писали о возможностях третьей версии, а на днях стал доступен обновленный ESXi Embedded Host Client v4.
Давайте посмотрим на его новые возможности.
Основное:
Новое меню Tools and links под разделом Help.
Механизм обновления теперь принимает URL или путь к хранилищу с zip-файлом метаданных, что позволяет обновлять собственно сам сервер ESXi, а не только накатывать VIB-пакеты. Подробнее об этом тут.
Локализация и интернационализация (французский, испанский, японский, немецкий, китайский и корейский).
Возможность отключить таймаут сессии (очен удобно, если клиент всегда открыт у вас на вкладке браузера).
Большое количество исправлений ошибок и мелких улучшений.
Операции с виртуальными машинами:
Работа со списком виртуальных машин была оптимизирована по производительности.
Возможность изменять расширенные настройки ВМ (advanced settings).
Возможность изменять настройки видеоадаптера ВМ.
Добавление девайса PCI pass-through (и его удаление).
Поддержка функции SRIOV для сетевых карточек.
Возможность изменения раскладки клавиатуры в браузере.
Поддержка комбинаций Cmd+a или Ctrl+a для выделения всех ВМ в списке.
Поддержка функций Soft-power и Reset для виртуальных машин, если установлены VMware Tools.
Операции с хостом:
Возможность изменять host acceptance level для установки сторонних пакетов.
Редактирование списка пользователей для исключений режима lockdown mode.
Изменение настроек системного свопа.
Скачать ESXi Embedded Host Client v4 можно по этой ссылке.
У большинства администраторов хотя бы раз была ситуация, когда управляющий сервер VMware vCenter оказывался недоступен. Как правило, этот сервер работает в виртуальной машине, которая может перемещаться между физическими хостами VMware ESXi.
Если вы знаете, где находится vCenter, то нужно зайти на хост ESXi через веб-консоль Embedded Host Client (который у вас должен быть развернут) и запустить/перезапустить ВМ с управляющим сервером. Если же вы не знаете, где именно ваш vCenter был в последний раз, то вам поможет вот эта статья.
Ну а как же повлияет недоступность vCenter на функционирование вашей виртуальной инфраструктуры? Давайте взглянем на картинку:
Зеленым отмечено то, что продолжает работать - собственно, виртуальные машины на хостах ESXi. Оранжевое - это то, что работает, но с некоторыми ограничениями, а красное - то, что совсем не работает.
Начнем с полностью нерабочих компонентов в случае недоступности vCenter:
Централизованное управление инфраструктурой (Management) - тут все очевидно, без vCenter ничего работать не будет.
DRS/Storage DRS - эти сервисы полностью зависят от vCenter, который определяет хосты ESXi и хранилища для миграций, ну и зависят от технологий vMotion/Storage vMotion, которые без vCenter не работают.
vMotion/SVMotion - они не работают, когда vCenter недоступен, так как нужно одновременно видеть все серверы кластера, проверять кучу различных условий на совместимость, доступность и т.п., что может делать только vCenter.
Теперь перейдем к ограниченно доступным функциям:
Fault Tolerance - да, даже без vCenter ваши виртуальные машины будут защищены кластером непрерывной доступности. Но вот если один из узлов ESXi откажет, то новый Secondary-узел уже не будет выбран для виртуальной машины, взявшей на себя нагрузку, так как этот функционал опирается на vCenter.
High Availability (HA) - тут все будет работать, так как настроенный кластер HA функционирует независимо от vCenter, но вот если вы запустите новые ВМ - они уже не будут защищены кластером HA. Кроме того, кластер HA не может быть переконфигурирован без vCenter.
VMware Distributed Switch (vDS) - распределенный виртуальный коммутатор как объект управления на сервере vCenter работать перестанет, однако сетевая коммуникация между виртуальными машинами будет доступна. Но вот если вам потребуется изменить сетевые настройки виртуальной машины, то уже придется прицеплять ее к обычному Standard Switch, так как вся конфигурация vDS доступна для редактирования только с работающим vCenter.
Other products - это сторонние продукты VMware, такие как vRealize Operations и прочие. Тут все зависит от самих продуктов - какие-то опираются на сервисы vCenter, какие-то нет. Но, как правило, без vCenter все довольно плохо с управлением сторонними продуктами, поэтому его нужно как можно скорее поднимать.
Для обеспечения доступности vCenter вы можете сделать следующее:
Защитить ВМ с vCenter технологией HA для рестарта машины на другом хосте ESXi в случае сбоя.
Использовать кластер непрерывной доступности VMware Fault Tolerance (FT) для сервера vCenter.
Как вы знаете, некоторое время назад вышло обновление платформы виртуализации VMware vSphere 6 Update 1, в котором были, в основном, только минорные обновления. Но было и важное - теперь виртуальный модуль VMware vCenter Server Appliance (vCSA) стало возможно обновлять путем монтирования к нему ISO-образа с апдейтом.
Давайте покажем упрощенный процесс обновления через смонтированный образ. Итак, соединимся с хостом vCSA по SSH (если у вас есть отдельный сервер Platform Services Controller, то коннектиться нужно к нему):
Далее скачаем обновление vCenter, в котором есть и обновление vCSA версии 6.0.0 (выберите продукт VC и в разделе VC-6.0.0U1-Appliance скачайтеVMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso):
Здесь надо пояснить, что это за обновления:
FP (Full patch) - это обновление всех компонентов vCenter, включая полноценные продукты, vCenter, vCSA, VMware Update Manager, PSC и прочее.
TP (Third party patch) - это обновление только отдельных компонентов vCenter.
Скачиваем патч FP (VMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso), после чего монтируем этот ISO-образ к виртуальной машине vCSA через vSphere Web Client или Embedded Host Client.
Далее возвращаемся к консоли vCSA:
Смонтировать ISO-образ можно также через PowerCLI с помощью следующих команд:
Далее выполняем следующую команду, если вы хотите накатить патчи прямо сейчас:
software-packages install --iso --acceptEulas
Либо патчи можно отправить на стейджинг отстаиваться (то есть пока обновить компоненты, но не устанавливать). Сначала выполняем команду отсылки на стейджинг:
software-packages install --iso --acceptEulas
Далее просматриваем содержимое пакетов:
software-packages list --staged
И устанавливаем апдейт со стейджинга:
software-packages install --staged
Если во время обновления на стейджинг или установки обновления возникли проблемы, вы можете просмотреть логи, выполнив следующие команды:
shell.set –enabled True shell cd /var/log/vmware/applmgmt/ tail software-packaged.log –n 25
Далее размонтируйте ISO-образ от виртуальной машины или сделайте это через PowerCLI следующей командой:
shutdown reboot -r "Updated to vCenter Server 6.0 Update 1"
Теперь откройте веб-консоль vCSA по адресу:
https://<FQDN-or-IP>:5480
И перейдите в раздел Update, где вы можете увидеть актуальную версию продукта:
Кстати, обратите внимание, что возможность проверки обновления в репозитории (Check URL) вернулась, и обновлять vCSA можно прямо отсюда по кнопке "Check Updates".
Мы уже писали о том, что последней версии решения для виртуализации настольных ПК VMware Horizon View 6.2 есть поддержка режима vGPU. Напомним, что это самая прогрессивная технология NVIDIA для поддержки требовательных к производительности графической подсистемы виртуальных десктопов.
Ранее мы уже писали про режимы Soft 3D, vSGA и vDGA, которые можно применять для виртуальных машин, использующих ресурсы графического адаптера на стороне сервера.
Напомним их:
Soft 3D - рендеринг 3D-картинки без использования адаптера на основе программных техник с использованием памяти сервера.
vDGA - выделение отдельного графического адаптера (GPU) одной виртуальной машине.
vSGA - использование общего графического адаптера несколькими виртуальными машинами.
Режим vSGA выглядит вот так:
Здесь графическая карта представляется виртуальной машине как программный видеодрайвер, а графический ввод-вывод обрабатывается через специальный драйвер в гипервизоре - ESXi driver (VIB-пакет). Команды обрабатываются по принципу "first come - first serve".
Режим vDGA выглядит вот так:
Здесь уже физический GPU назначается виртуальной машине через механизм проброса устройств DirectPath I/O. То есть целый графический адаптер потребляется виртуальной машиной, что совсем неэкономно, но очень производительно.
В этом случае специальный драйвер NVIDIA GPU Driver Package устанавливается внутри виртуальной машины, а сам режим полностью поддерживается в релизах Horizon View 5.3.х и 6.х (то есть это давно уже не превью и не экспериментальная технология). Этот режим работает в графических картах K1 и K2, а также и более свежих адаптерах, о которых речь пойдет ниже.
Режим vGPU выглядит вот так:
То есть встроенный в гипервизор NVIDIA vGPU Manager (это тоже драйвер в виде пакета ESXi VIB) осуществляет управление виртуальными графическими адаптерами vGPU, которые прикрепляются к виртуальным машинам в режиме 1:1. В операционной системе виртуальных ПК также устанавливается GRID Software Driver.
Здесь уже вводится понятие профиля vGPU (Certified NVIDIA vGPU Profiles), который определяет типовую рабочую нагрузку и технические параметры десктопа (максимальное разрешение, объем видеопамяти, число пользователей на физический GPU и т.п.).
vGPU можно применять с первой версией технологии GRID 1.0, которая поддерживается для графических карт K1 и K2:
Но если мы говорим о последней версии технологии GRID 2.0, работающей с адаптерами Tesla M60/M6, то там все устроено несколько иначе. Напомним, что адаптеры Tesla M60 предназначены для Rack/Tower серверов с шиной PCIe, а M6 - для блейд-систем различных вендоров.
Технология NVIDIA GRID 2.0 доступна в трех версиях, которые позволяют распределять ресурсы между пользователями:
Характеристики данных лицензируемых для адаптеров Tesla изданий представлены ниже:
Тут мы видим, что дело уже не только в аппаратных свойствах графической карточки, но и в лицензируемых фичах для соответствующего варианта использования рабочей нагрузки.
Каждый "experience" лицензируется на определенное число пользователей (одновременные подключения) для определенного уровня виртуальных профилей. Поэтому в инфраструктуре GRID 2.0 добавляется еще два вспомогательных компонента: Licensing Manager и GPU Mode Change Utility (она нужна, чтобы перевести адаптер Tesla M60/M6 из режима compute mode в режим graphics mode для работы с соответствующим типом лицензии виртуальных профилей).
Обратите внимание, что поддержка гостевых ОС Linux заявлена только в последних двух типах лицензий.
На данный момент сертификацию драйверов GRID прошло следующее программное обеспечение сторонних вендоров (подробнее об этом тут):
Спецификации карточек Tesla выглядят на сегодняшний день вот так:
Поддержка также разделена на 2 уровня (также прикрепляется к лицензии):
Руководство по развертыванию NVIDIA GRID можно скачать по этой ссылке, ну а в целом про технологию написано тут.
Для тех из вас, кто еще не обновил свою инфраструктуру на последнюю версию VMware vSphere 6, компания VMware приготовила очередной пакет исправлений VMware vSphere 5.5 Update 3b. На самом деле, это просто патч VMware ESXi 5.5 patch ESXi550-201512001, в котором произошли некоторые изменения в плане безопасности, а также исправлены ошибки.
Среди заявленных фич, касающихся security, основная - это отключенный по умолчанию SSL третьей версии (SSLv3). Отключили его (как в клиенте, так и в сервере) потому, что он считается устаревшим, и его поддержка уже не предоставляется в большинстве Enterprise-продуктов (об этом можно почитать в RFC 7568).
Внимание! Обязательно следуйте рекомендованной последовательности обновления продуктов VMware, то есть сначала обновите vCenter до версии 5.5 Update 3b и только потом ESXi 5.5 до версии Update 3b, чтобы избежать проблем с отключением хостов от сервера управления vCenter.
Также помните, что VMware View Composer версии ниже 6.2 не будет работать с хостами ESXi 5.5 Update 3b.
На блогах VMware появился интересный пост про производительность виртуальных машин, которые "растянуты" по ресурсам на весь физический сервер, на котором они запущены. В частности, в посте речь идет о сервере баз данных, от которого требуется максимальная производительность в числе транзакций в секунду (см. наш похожий пост о производительности облачного MS SQL здесь).
В данном случае речь идет о виртуализации БД с типом нагрузки OLTP, то есть обработка небольших транзакций в реальном времени. Для тестирования использовался профиль Order-Entry, который основан на базе бенчмарка TPC-C. Результаты подробно описаны в открытом документе "Virtualizing Performance Critical Database Applications in VMware vSphere 6.0", а здесь мы приведем основные выдержки.
Сводная таблица потерь на виртуализацию:
Метрика
Нативное исполнение нагрузки
Виртуальная машина
Пропускная способность транзакций в секунду
66.5K
59.5K
Средняя загрузка логических процессоров (72 штуки)
84.7%
85.1%
Число операций ввода-вывода (Disk IOPS)
173K
155K
Пропускная способность ввода-вывода дисковой подсистемы (Disk Megabytes/second)
929MB/s
831MB/s
Передача пакетов по сети в секунду
71K/s receive
71K/s send
63K/s receive
64K/s send
Пропускная способность сети в секунду
15MB/s receive
36MB/s send
13MB/s receive
32MB/s send
А вот так выглядит график итогового тестирования (кликабельно):
Для платформы VMware ESXi 5.1 сравнивалась производительность на процессоре микроархитектуры Westmere, а для ESXi 6.0 - на процессорах Haswell.
Результаты, выраженные в числе транзакций в секунду, вы видите на картинке. Интересно заметить, что ESXi версии 6.0 всерьез прибавил по сравнению с прошлой версией в плане уменьшения потерь на накладные расходы на виртуализацию.
А вот так выглядят усредненные значения для версий ESXi в сравнении друг с другом по отношению к запуску нагрузки на нативной платформе:
Ну и несложно догадаться, что исследуемая база данных - это Oracle. Остальное читайте в интереснейшем документе.

 RSS
RSS






















































































































{kind=link}

